변수의 명명규칙
변수의 이름처럼 프로그래밍에서 사용하는 모든 이름은 식별자라고 하며, 식별자는 같은 영역 내에서 서로 구분될 수 있어야 한다. 변수의 명명규칙은 필수적인 규칙과 권장되는 규칙이 존재한다.
<필수적인 규칙들>
- 대소문자가 구분되며 길이에 제한이 없다.
- 예약어를 사용해서는 안 된다.
- 숫자로 시작해서는 안 된다.
- 특수문자는 '_'와 '$'만을 허용한다.
<권장되는 규칙들>
- 클래스 이름의 첫 글자는 항상 대문자로 한다.
- 변수와 메서드의 이름의 첫 글자는 항상 소문자로 한다.
- 여러 단어로 이루어진 이름은 단어의 첫 글자를 대문자로 한다. (IndexOf)
- 상수의 이름은 모두 대문자로 한다. 여러 단어로 이루어진 경우 '_'로 구분한다. (MAX_NUMBER)
※ 예약어는 프로그래밍언어의 구문에 사용되는 단어를 의미하며, 클래스나 변수, 메서드의 이름으로 사용할 수 없다.
변수의 타입
변수의 타입은 크게 기본형과 참조형 두 가지로 나뉜다.
기본형 (primitive type) :
계산을 위한 실제 값을 정하며, 논리형(boolean), 문자형(char), 정수형(byte, short, int, long), 실수형 (float, double)이 있다.
참조형 (reference type) :
객체의 주소를 저장하며 기본형을 제외한 나머지 타입이 해당된다.
기본형에는 8개의 타입이 있으며, 논리형을 제외한 다른 기본형들은 서로 연산 및 변환이 가능하다. 문자형은 문자를 정수(유니코드)로 저장하기 때문에 정수형과 크게 다르지 않다.
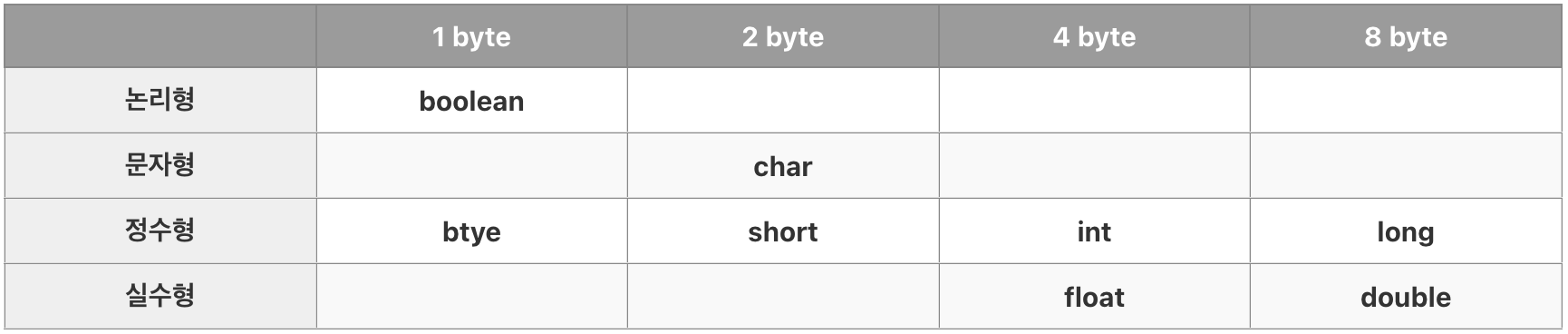
※ int는 CPU가 가장 효율적으로 처리할 수 있는 타입이다.
상수와 리터럴
상수는 변수처럼 값을 저장할 수 있는 공간이지만, 한 번 값을 저장하면 다른 값으로 변경할 수 없다. 상수의 선언은 타입 앞에 'final'을 붙여주면 된다.
리터럴은 변수나 상수에 실제 저장된 값(1, 2, 'A' 등) 자체를 의미한다. Java에선 상수를 다른 개념으로 정의하였기 때문에 기존의 상수를 지칭할 필요가 있기 때문에 리터럴이라는 용어를 사용하였다.

※ 상수를 사용하면 상수 값의 수정이 필요한 경우, 상수를 사용하는 곳을 신경쓸 것 없이 상수를 정의한 부분의 값만 변경하면 된다. 즉, 코드에 대한 유지보수가 쉬워진다.
<리터럴에 붙는 접두사, 접미사>

리터럴의 추가적인 특징은 다음과 같다.
- 정수형 리터럴의 중간에 구분자 '_'를 넣을 수 있다. (0xFFFF_FFFF_FFFF_FFFFL)
- 기호 p, P를 이용해 실수 리터럴을 16진 지수형태로 표현할 수 있다. p가 포함된 리터럴은 실수형이다. (0x1p1 = (1x16⁰) x 2¹)
- 기호 e, E를 이용해 소수점이나 10의 제곱을 표현할 수 있다. (2.0e2 = 20)
- 리터럴의 값이 변수의 타입의 범위를 벗어나거나, 리터럴의 타입이 변수의 타입보다 저장범위가 넓으면 컴파일 에러가 발생한다.
진법
비트(bit, binary digit)는 한 자리의 2진수를 의미하며, 1비트는 컴퓨터가 값을 저장할 수 있는 최소단위이다.
바이트(byte)는 테이터의 기본 단위로 1비트 8개의 크기를 가진다.
워드(word)는 CPU가 한 번에 처리할 수 있는 데이터의 크기로 CPU의 성능에 따라 크기가 달라진다.
진수 변환과 보수법에 대해선 링크로 대체한다. [진수변환] [보수법]
기본형
1. 논리형

2. 문자형

※ 특수 문자를 다루기 위해선 '\'를 추가하여 저장한다. ex) tab : \t, backspace : \b, 역슬래쉬 : \\, 작은따옴표 : \', 큰따옴표 : \"
3. 정수형

※ JVM의 피연산자 스택이 피연산자를 4 byte 단위로 저장하기 때문에 크기가 4 byte보다 작은 자료형의 값을 계산할 때는 4 byte로 변환 후 연산이 수행된다. 기본적으로는 int 형을 사용하고, 메모리 절약이 우선적일 때는 byte나 short를 사용한다.
※ 오버플로우(overflow)는 자료형이 표현할 수 있는 값의 범위를 넘어서는 것을 의미한다. 예를 들면, int의 양의 최대값 2147483647에 1을 더하면 -2147483648로 값이 변하게 된다.
4. 실수형

※ 실수형에서 오버플로우가 발생하는 경우 변수의 값은 무한대가 된다.
※ 언더플로우(underflow)는 실수형의 양의 최소값보다 작은 값이 되는 경우를 의미하며, 변수의 값은 0이 된다.
<자료형 기본값 정리>

형변환
형변환은 변수 또는 상수의 타입을 다른 타입으로 변환하는 것을 의미한다.
double tmp = 1.345;
int tmp2 = (int)tmp;
//최종적으로 tmp2의 값은 1이 저장
기본형과 참조형 간의 형변환은 불가능하며, 기본형에서도 boolean을 제외한 나머지 타입 간의 형변환이 가능하다.
형변환에서 주의할 점은 자신보다 작은 크기의 자료형으로 형변환할 경우 값의 손실이 발생할 수 있다는 점이다. 위의 예제에서도 double을 int로 변환하는 과정에서 소수점이 사라지고 1이 저장된 것을 알 수 있다. 물론 실수형, 정수형 간의 형변환과 정수형 간의 형변환에는 차이가 있지만 여기선 깊이 다루지 않는다.
※ 형변환을 명시하지 않아도 컴파일러가 생략된 형변환을 자동적으로 추가해준다. 하지만 저장하려는 값이 자료형의 크기보다 큰 경우는 에러가 발생하게 된다. 이 경우 명시적으로 형변환을 해주는 경우 개발자가 의도한 것으로 판단하여 에러를 발생시키지 않는다.
int tmp = 3456789765432134567876543213456; //에러
int tmp = (int)3456789765432134567876543213456; //OK
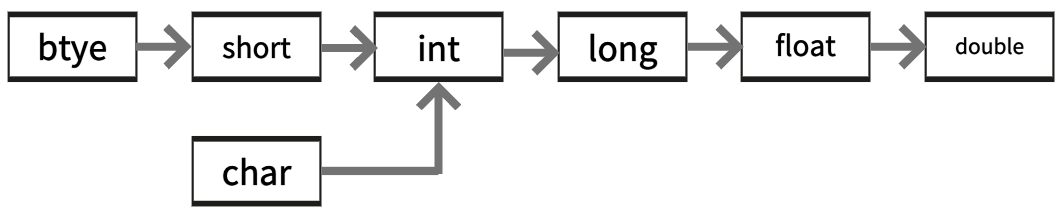
※ 자동 형변환은 기존의 값을 최대한 보존할 수 있는 타입으로 형변환을 수행한다. float은 long보다 표현 가능한 값의 범위가 크기 때문에 long에서 float으로 자동 형변환이 가능하다. 하지만 화살표의 역방향으로의 형변환은 명시적인 형변환이 필요하며, byte, short와 char 간의 형변환은 부호 비트의 유무로 인해 어떤 경우든 손실이 발생하여 자동 형변환이 불가능하다.
Q&A
Q. 기본형 타입의 종류와 크기는?
A. 논리형 boolean, 문자형 char, 정수형 byte, short, int, long, 실수형 float, double 이 있으며 순서대로 1, 2, 1, 2, 4, 8, 4, 8 byte의 크기를 가진다.
Q. 상수와 리터럴의 차이는 무엇인가?
A. 상수는 저장된 값을 수정할 수 없는 변수를 의미하고, 리터럴은 변수에 저장되는 값 자체를 의미한다.
Q. 상수를 왜 사용할까?
A. 상수의 값을 변경해야 하는 경우 해당 상수를 선언한 부분만 수정하면 되기에 코드에 대한 유지보수가 쉽다.
Q. 언더플로우란 무엇인가?
A. 자료형이 표현할 수 있는 값의 범위를 벗어난 경우를 의미한다.
Q. float과 double의 차이는?
A. float은 4 byte, 7의 정밀도, 상대적으로 빠른 연산속도와 메로리 효율을 가진다. double은 8 byte 15의 정밀도, 상대적으로 더 큰 표현 범위와 오차 범위를 가진다.
참고자료
- Java의 정석
'개념서 > Java' 카테고리의 다른 글
| [Java] 상속 (0) | 2022.06.10 |
|---|---|
| [Java] 객체지향 프로그래밍 I (0) | 2022.06.06 |
| [Java] 조건문, 반복문, 배열 (0) | 2022.05.28 |
| [Java] 연산자 (0) | 2022.05.27 |
| [Java] 시작하기 (0) | 2022.05.21 |




댓글